Apple’s AI getting crazy and nobody’s talking about it
they just open sourced FastVLM + MobileCLIP2, can do realtime VIDEO captioning with phone camera.. runs 100% local on your phone, 85x faster, 3.4x smaller…
free to test and download, link in comment
let's break down:
here’s the problem with AI models, if you bump up the image resolution, the model gets smarter, more pixels, more detail
but the downside is, it gets slower, ’cause higher-res images take longer to process, and you end up with more visual tokens that slow down the LLM setup

some tests here, keeping same data, recipe, LLM but swap out the vision encoder
they compared with ViT‑L/14 and SigLIP‑SO400, a fully convolutional ConvNeXT, and hybrid FastViT models
FastViT is like 8× smaller and 20× faster than ViT‑L/14 while staying just as smart
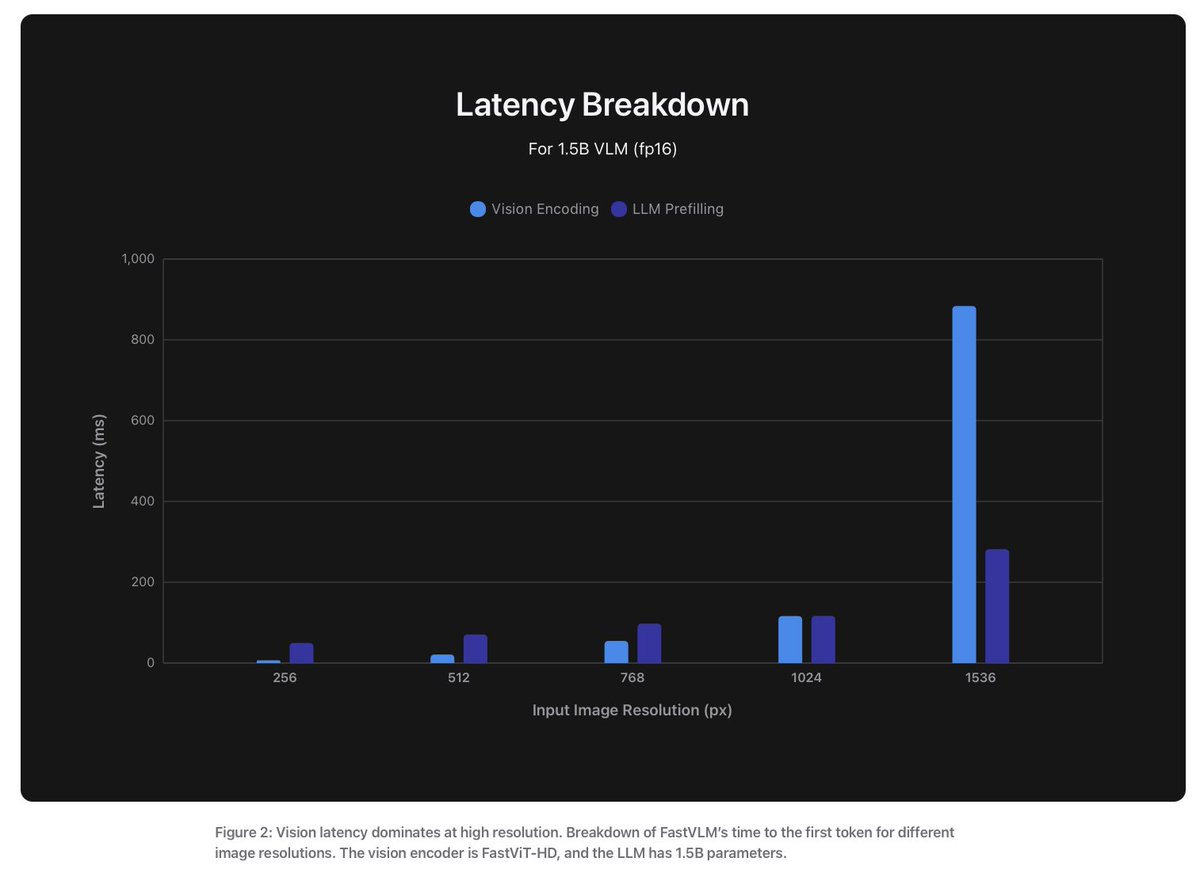
FastViT’s cool, but when use high resolution, it starts to slow down
so they built FastViTHD, ditching the naive scaling and instead adding an extra stage, training it with MobileCLIP, and basically making fewer but better tokens
when they paired different image res, LLM sizes (0.5B, 1.5B, 7B), and both encoders, FastViTHD came out way ahead
in some cases, it’s up to 3× faster for the same accuracy
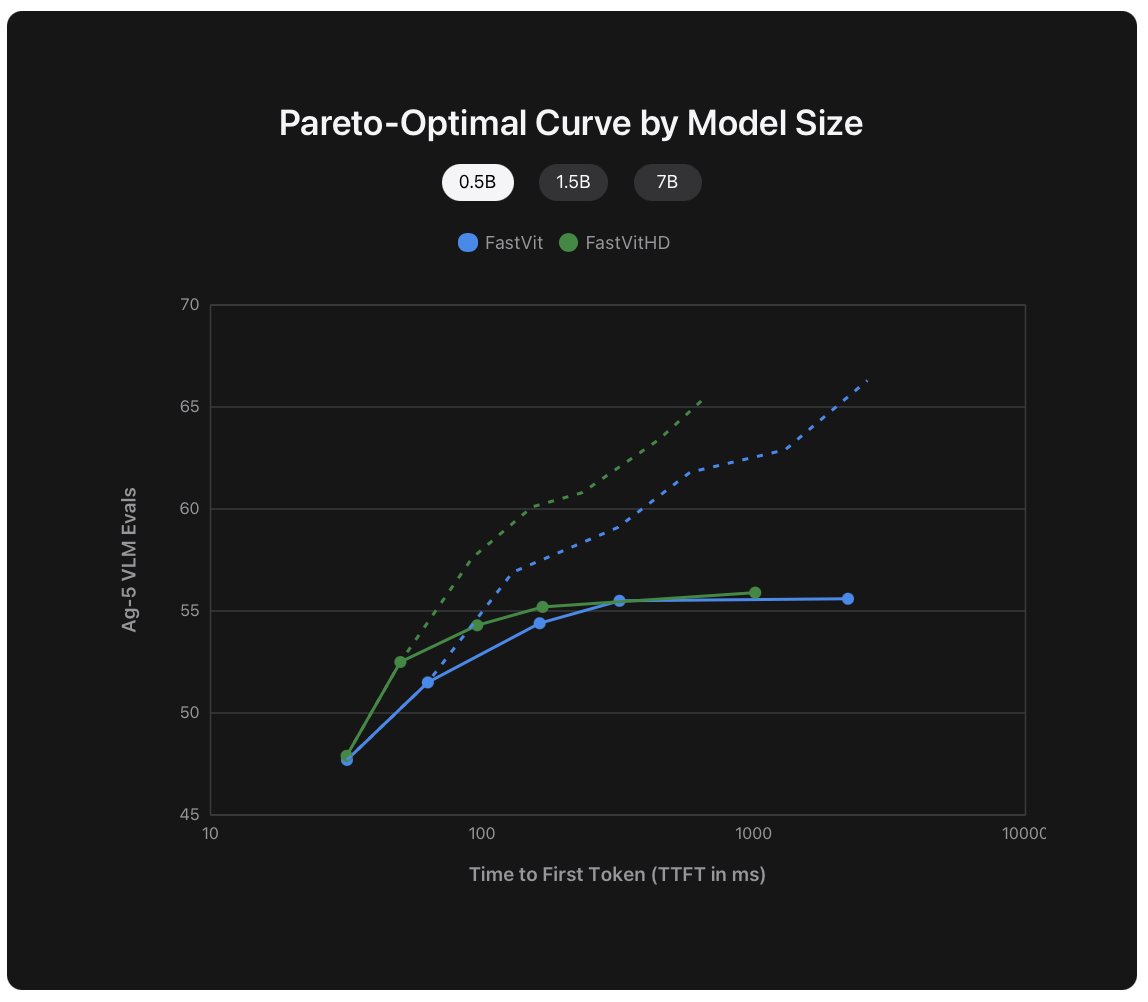
here’s where FastVLM comes in
they slap an MLP to project visual tokens from FastViTHD into the LLM’s world
the result: way fewer tokens (like 4× less than FastViT, 16× less than ViT‑L/14 at 336‑pixel res). I mean, that’s a big dropping in token count and complexity, while keeping things snappy

What’s cool is that they didn’t need to use those fancy token‑pruning or merging tricks that others use to speed stuff up. FastVLM just naturally delivers better accuracy across token counts since it’s generating higher‑quality tokens. Simpler to deploy and better results—win win
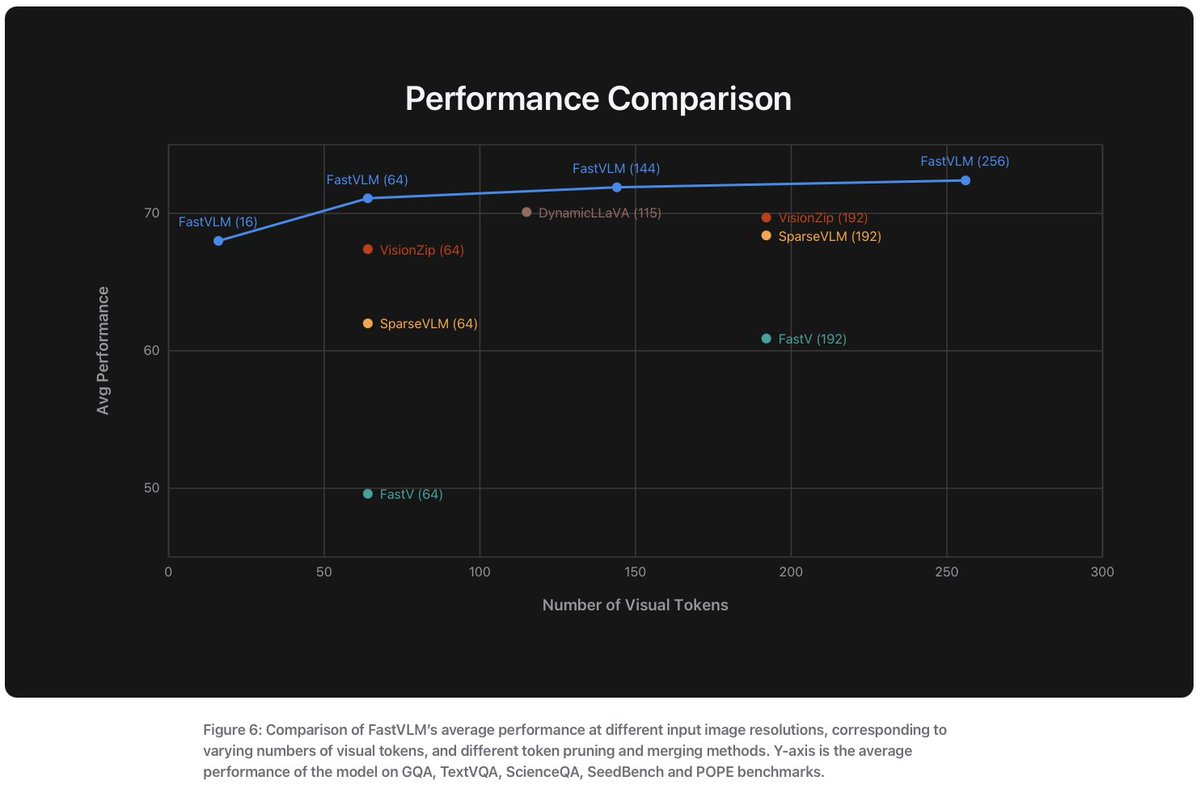
there’s also this thing called dynamic tiling
your classic AnyRes approach where you chop up images into tiles and process them separately, then feed everything to the LLM
they tested that with FastVLM too. turns out, without tiling, FastVLM still gives a smoother accuracy‑latency tradeoff
only at super high resolutions does tiling help much, and even then only with fewer tiles (like 2×2)

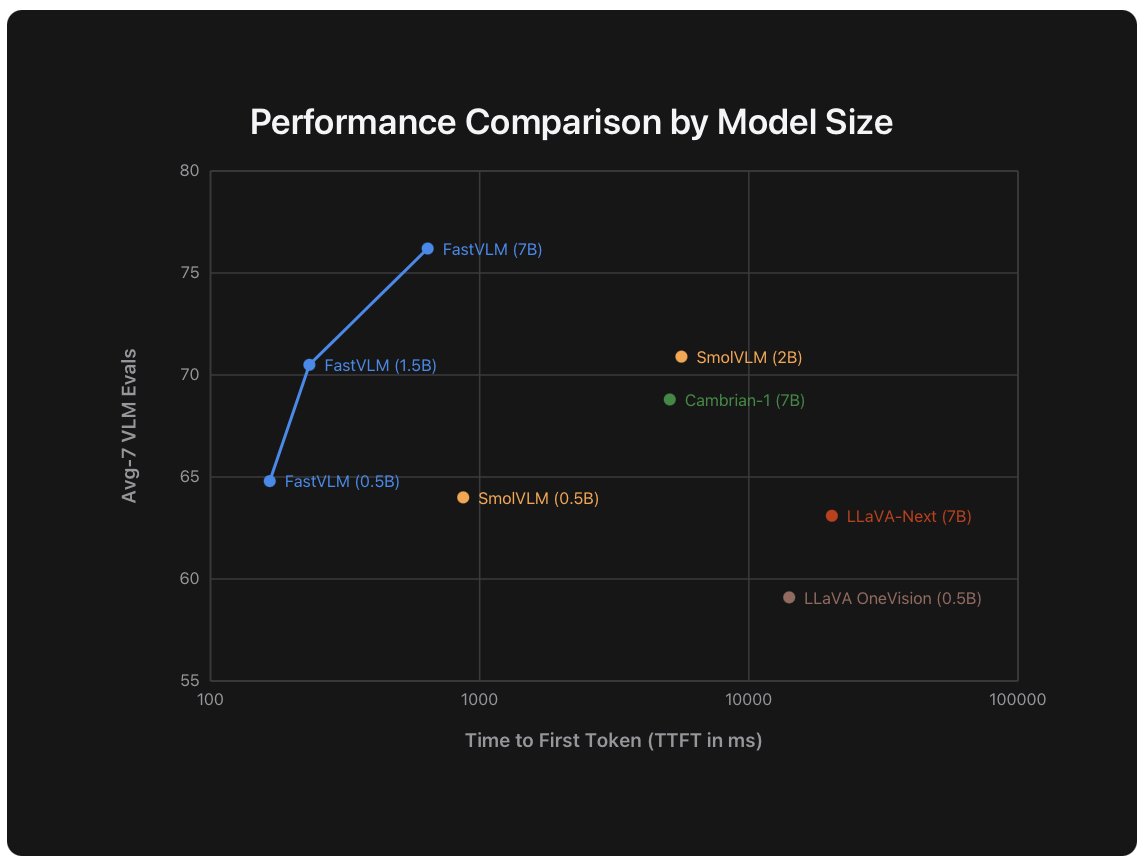
FastVLM is faster and more accurate than popular VLMs of the same size
FastVLM beat other models in both speed and smarts
it’s 85× faster than LLava‑OneVision (0.5B), 5.2× faster than SmolVLM (around 0.5B), and 21× faster than Cambrian‑1 (7B)
that’s a ridiculous leap
they even released an iOS/macOS demo so you can actually try it on your iPhone GPU
that’s wild..
link to models:
- FastVLM: https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
- MobileCLIP2: https://huggingface.co/collections/apple/mobileclip2-68ac947dcb035c54bcd20c47
Demo (+ source code): https://huggingface.co/spaces/apple/fastvlm-webgpu
if you found this inspiring,
follow @EHuanglu for more great stuff
and give it a like & repost to let more people know 👇
