https://t.co/KFxhcvvNCP
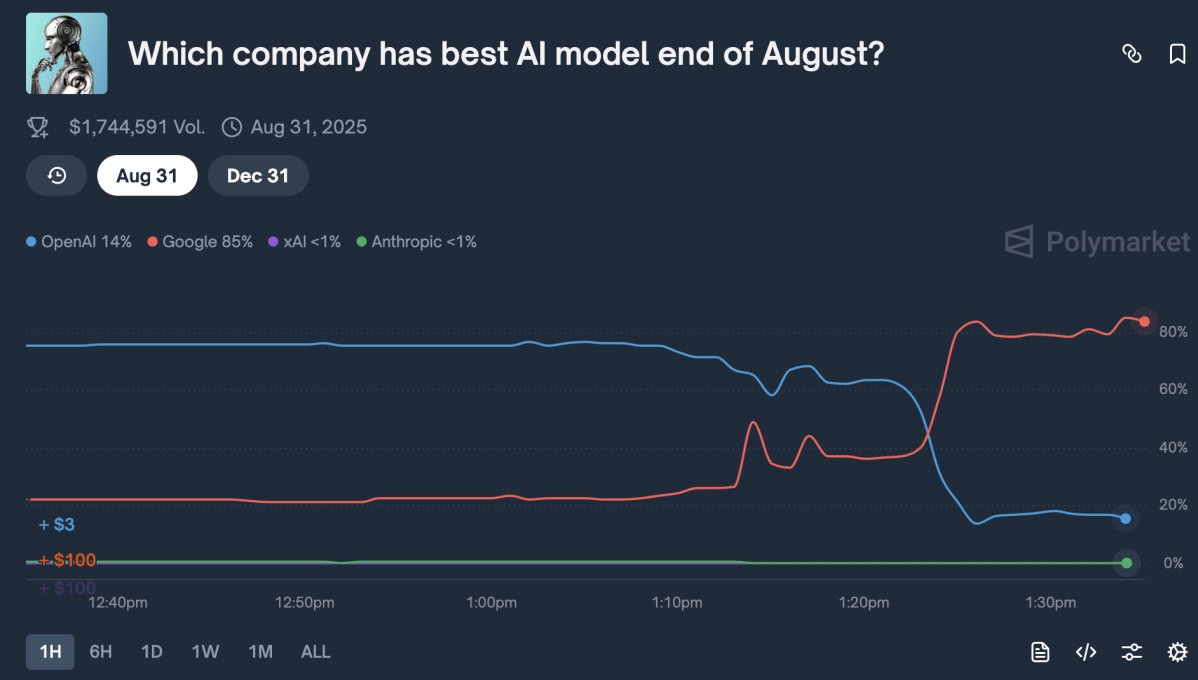
My prediction is based purely on my read on the psychology behind the hype from Sam and the OAI team
So far it feels a LOT better than 4o but difficult to tell where it lies relative to Claude 4
I'd guess probably practically worse than Claude 4, it made a mistake there that I know Claude 4 make
Oh, it made another absolutely idiotic mistake
I gave it huggingface urls for a model download and it inexplicably changed the base urls to another repo
What??!
It's free in Cursor but free isn't worth worrying about shit like that
I will jump at the opportunity to replace Claude but it feels like this ain't it, losing confidence rapidly
And the two mistakes it made are very unpredicable, at least when cursor fails you can tell why - skill issue mostly
This is similar to O3/Grok4 fails, they just tend to be absolutely unhinged
I tried to get it to do a task but it instead wrote documentation about it
It then kept on pausing at each step despite me insisting it should continue and complete the task
Got halfway there and grew frustrated so revered to beginning with Claude 4 which did it in one go
Anthropic and Google to a lesser extent feel far better culturally at the nuance of making a powerful model useful
Though OAI are still miles ahead of XAI
Grok4 is probably the most raw powerful model that is practically crappy to use
Overall GPT5 is still objectively impressive
But probably worse than Claude 4 practically and earlier versions of 2.5
And will definitely be worse than whatever Google have next if they continue their arc (and don’t cripple their model on post training optimisation again)
I need to try it on more writing and creative tasks
On some poetry tests it was interesting but also felt random/unintentional and succumbed to some of the stereotyping stuff of older models
Preferred kimi k2 in 3 blind head to heads
