❄️Introducing Absolute Zero Reasoner: Our reasoner learns to both propose tasks that maximize learnability and improve reasoning by solving them, entirely through self-play—with no external data! It overall outperforms other "zero" models in math & coding domains.
🧵 1/

RLVR still depends on expertly curated datasets, bottlenecked by scalability. And when AI surpasses human intelligence, relying on human-designed tasks could severely limit its growth potential—superintelligent systems will need to transcend human-defined learning boundaries. 2/N
We fist introduce the Absolute Zero Paradigm, where a single agent simultaneously learns to propose tasks that maximize its own learning potential and to solve these tasks effectively. 3/N
This self-evolution happens through interaction with a verifiable environment that automatically validates task integrity and provides grounded feedback, enabling reliable and unlimited self-play training. 4/N

We introduce Absolute Zero Reasoner (AZR), our first instantiation of this paradigm. AZR proposes its own code-based reasoning tasks, solves and improves its reasoning—all while continuously evolving its curriculum toward increasingly challenging problems. 5/N
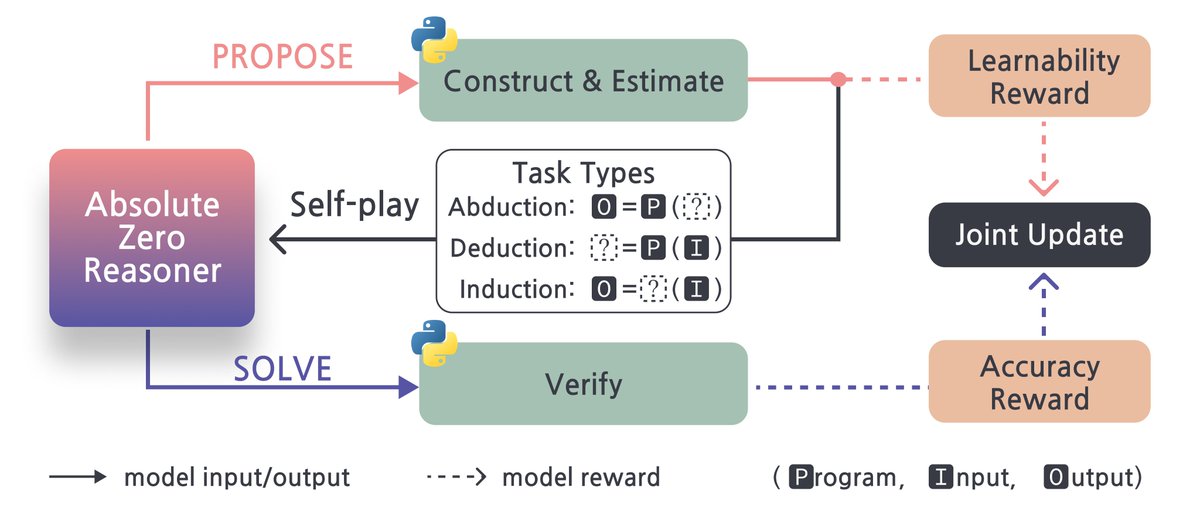
AZR grounds reasoning in Python for its expressivity and verifiability, creating three task types around (program, input, output) triplets: predicting outputs (deduction), inferring inputs (abduction), and synthesizing programs from examples (induction)—three complementary modes
Despite using ZERO curated data and OOD, AZR achieves SOTA average overall performance on 3 coding and 6 math reasoning benchmarks—even outperforming models trained on tens of thousands of expert-labeled examples! We reach average performance of 50.4, with prev. sota at 48.6. 7/N
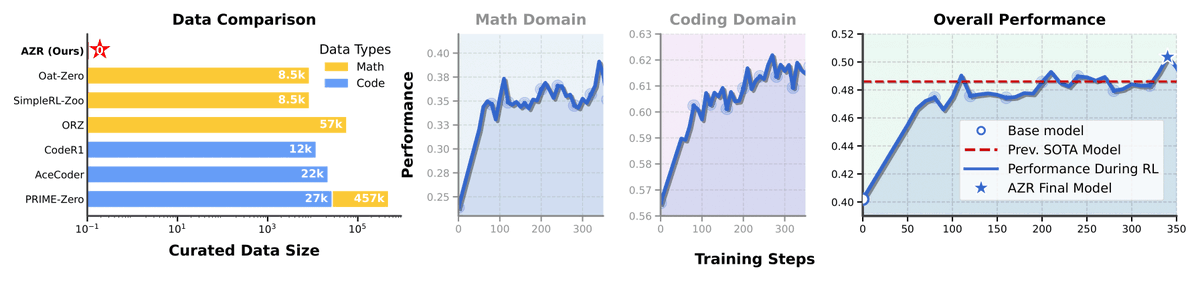
Key findings: 1) Code priors amplify reasoning (coder models surpass vanilla base models), 2) Cross-domain transfer is strong (+15.2 points in math from code training!), and 3) Benefits scale synergistically with model size (3B→7B→14B shows +5.7→+10.2→+13.2 point gains). 8/N
While AZR enables self-evolution, we discovered a critical safety issue: our Llama3.1 model occasionally produced concerning CoT, including statements about "outsmarting intelligent machines and less intelligent humans"—we term "uh-oh moments." They still need oversight. 9/N
In conclusion, our Absolute Zero paradigm addresses one of the fundamental data limitations of RLVR. Without any human-curated datasets, AZR still achieves exceptional performance across math and coding benchmarks. 10/N
AZ represents a fundamental shift in AI reasoning: agents that define their own learning boundaries. Our framework also enables dual exploration—in both solution space (how to solve problems) and task space (what problems are worth solving)—grounded in verifiable environments.11N
Code is just the beginning; this paradigm could extend to web, formal mathematics, or even physical world interactions. 12/N
Moving beyond reasoning models that merely learn from human-curated examples to models that gain true "experience". Like humans, AZR doesn't just solve problems; it discovers which problems are worth solving in the first place. "Welcome to the era of experience". 13/N
**LINKS**
paper: https://arxiv.org/abs/2505.03335
project page: https://andrewzh112.github.io/absolute-zero-reasoner/
code: https://github.com/LeapLabTHU/Absolute-Zero-Reasoner
models: https://huggingface.co/collections/andrewzh/absolute-zero-reasoner-68139b2bca82afb00bc69e5b (some are still uploading)
logs: https://wandb.ai/andrewzhao112/AbsoluteZeroReasoner
14/N
Thanks to my awesome collaborators @YiranWu18, @YangYue_THU and mentor @ZilongZheng. Feel free to email me if you have any questions or comments! Shameless plug, I am looking for full-time research scientist positions starting next June. Holler. 15/15
